4. Begin with the end in mind
For me, Architecture is Day 1, and Operations is Day 2. Day 1 happens before Day 2. By Architecture, I mean the detail work, including building and commissioning the system. While the high level marketecture1 is defined during Day 0 (Planning), the real architecture work is done on Day 1.
However, if we think deeper, Day 2 impacts Day 0, which is Planning. The reason is the End State drives your Plan. Your Plan drives your Architecture. So it’s 2 -> 0 -> 1, not 0 -> 1 -> 2.
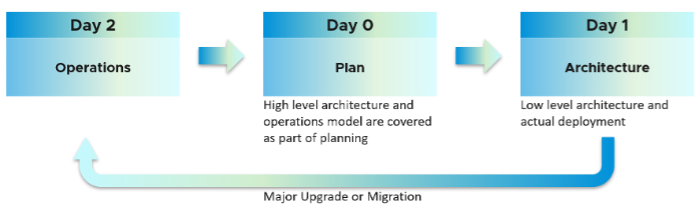
Let’s use an example to illustrate how Day 2 impacts Day 0, which in turn impacts Day 1.
Say you are an internal cloud provider, and you plan to charge per VM. You plan to have 2 classes of offerings:
- Gold: suitable for production workloads. Performance optimized.
- Silver: suitable for non-production workloads. Cost optimized.
For Gold, you plan to not overcommit CPU and RAM. If 1 CPU typically uses 4 GB RAM, then a 40-core ESXi host will only need 160 GB. If you buy a host with 1 TB RAM, then you may end up in a position where you are not able to sell the remaining 864 GB as you have no vCPU to sell. This means your hardware specification is impacted. That’s an example of how Day 2 impacts Day 0.
For Silver, you plan to overcommit 4:1 for CPU and 2:1 for memory.
- You assume that 1 vCPU typically uses 4 GB RAM. Your customers are allowed to buy more or less memory, so this 4:1 ratio between CPU and RAM are just your planning guide.
- You plan to run vSAN with dedupe + NSX + vSphere Replication. You also expect heavy IO VMs, which requires kernel processing. For all these supporting, non-business workloads, you allocate 8 cores and 64 GB RAM.
- If you buy a 64-core ESXi, you have 56 cores left and you will be able to sell 224 vCPU.
- These 224 vCPU will need 896 GB RAM. Since you overcommit 2:1, you need 448 GB for VM. Total RAM you need is 448 + 64 = 512 GB.
- That means the hardware spec you need is 64 core and 512 GB RAM. If you buy more RAM than this, you may not be able to sell this extra RAM as you may not have vCPU to accompany them.
The above 2 examples show how your hardware specification can’t be decided without considering the average VM profile and the overcommit ratio you plan.
You also promise the concept of Availability Zone for Gold class, as they host mission critical business services. Your company policy for Business Continuity dictates that in the event of an entire cluster failure, you plan to cap the number of VMs affected. If you limit to say 300 production VMs, then your cluster size should not be too big as you won’t be able to fully utilize the resource. I’ve seen many 32-node production clusters running 1000-2000 VMs.
In your service offering, you include the ability for the customers to check their own VM health, and how their VMs are served by the underlying platform. This means your architecture needs to know how to associate tenants with their VMs. You need to have a tagging standard, such as business unit, department, contact name.
Your CIO wants a live information projected for his peers to see on how IT is serving the business. This requires you to think of the Key Performance Indicators (KPI)2. How do you know the IaaS is performing fast enough for its consumers? How do you prove that you are meeting the Service Level Agreement (SLA) you promised?
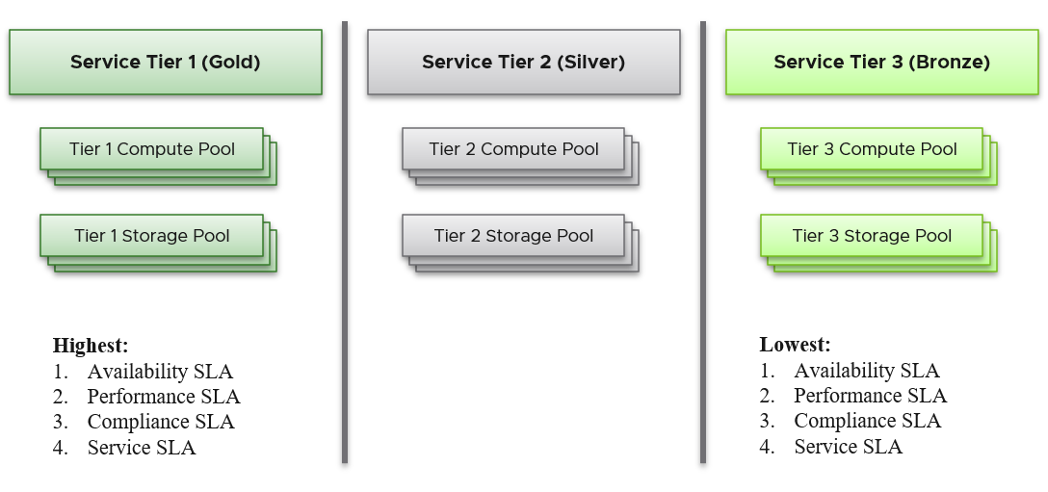
From the performance management point of view, vSphere cluster is the smallest logical building block of the resources. While the resource pool and VM Host affinity can provide a smaller slice, they are operationally complex, and they cannot deliver the promised quality of IaaS service. Resource pool cannot provide a differentiated class of service. For example, your SLA states that Gold is two times faster than silver because it is charged at 200% more. The resource pool can give Gold two times more shares. Whether those extra shares translate into half the CPU readiness cannot be determined up front.
It’s important to reflect the business in your operations. Create a hierarchical structure where the operations team and tenants can easily find the relevant VMs. These users will be driven by business applications, so your IaaS needs to be designed around that. The following structure shows Business Unit as the top folder. Each business unit can have 1 or more departments (Business Unit C spans 3 departments in the diagram below). Each department owns multiple business applications. A business application typically consists of multiple tiers (e.g. web tier, app tier, database tier).
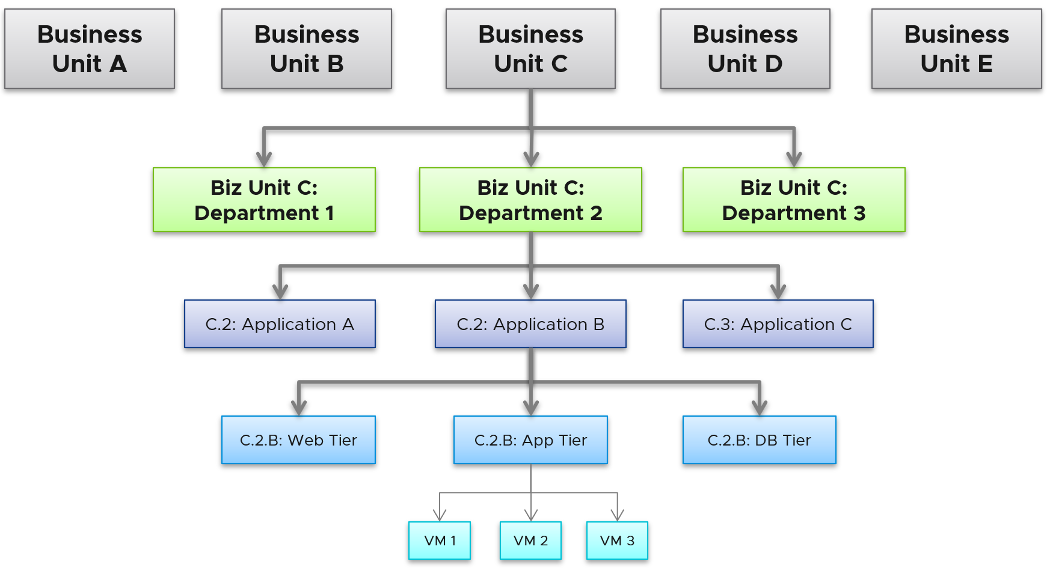
The limitation of the above is reorganisation. You will need to rename, move folders to the new parent folders, and delete folders. For example, if Business Unit B merges with Business Unit C and the combined entity has a new name, then you need to rename one of them, and delete the other.
Last but not least, you need to account for problem. Real problems happen in Day 2 as that’s when you have business workloads doing revenue generating transactions. Do not architect something you are not willing to troubleshoot. Think of the roles and skills required to operate your architecture. Provide the necessary visibility3 into each component and define what constitutes health, risk and efficiency.
I hope the above examples show that Day 2 is where you want to start. Begin with the end in mind, says a famous quote.
Did you notice something missing in the discussion above?
Yes, I did not cover Automation.
Why is that?
For me, that’s part of Architecture. You should not automate what you cannot operate. So, automation is not part of operations. Automation is a feature of your Architecture, meaning you design the system with automation in mind. Using an analogy, it’s like a plane with many automation features. Fly-by-wire. That’s a feature of the plane. How you operate the plane, so passengers arrive at the destination safely, comfortably and on time, that’s operation.
Marketing architecture. A light reference to PowerPoint based diagram that lacks details to be implemented. ↩︎
I understand the difference between SLI, SLO, SLA, KAI and KPI. Not using SLI and SLO for PCMCIA reason (People Can’t Manage Computer Industry Acronyms). Being precise is good. But using too many jargons is adding complexity. ↩︎
Some people use the term Observability, and create unnecessary confusion with Monitoring. This is yet another example of PCMCIA. If we really want to split hair, the term debuggability carries more value as just because you can observe a system does not mean it’s debuggable. ↩︎
This page was last updated on August 2, 2021 by Gary Diamond with commit message: "Added missing word "one"."
VMware and the VMware taglines, logos and product names are trademarks or registered trademarks of VMware in the U.S. and other countries.